No products in the cart.
معرفی زبان اچ تی ام ال – HTML (HyperText Markup Language)

معرفی اچ تی ام ال – HTML
HyperText Markup Language که عموما به HTML خلاصه می شود، یک زبان نشانه گذاری استاندارد است که برای ایجاد صفحات وب مورد استفاده قرار می گیرد. HTML به همراه CSS و JavaScript یک تکنولوژی بنیادی برای ساخت صفحات وب و همچنین ایجاد رابط های کاربری برای برنامه های موبایل و وب است. مرورگرهای وب می توانند فایل های HTML را بخوانند و آنها را به صفحات وب قابل خواندن یا شنیدن تبدیل کنند. HTML ( اچ تی ام ال ) توصیف کننده ساختار یک وبسایت از نظر معنایی است و قبل از ظهور Cascading Style Sheets (CSS)، حاوی نشانه هایی برای نمایش یا ظاهر سند (صفحه وب) بود که باعث می شود بیشتر یک زبان نشانه گذاری باشد تا زبان برنامه نویسی.
عناصر HTML، زیربنای صفحات HTML هستند. HTML تصاویر و دیگر اشیا را در خود نگه می دارد و می توان از آن برای ایجاد فرم های تعاملی استفاده کرد. HTML با مشخص کردن معانی ساختاری برای متونی از قبیل سشرصفحه، پاراگراف، فهرست ها، لینک ها، نقل قول ها و آیتم های دیگر، واسطه ای را برای ایجاد اسناد ساخت یافته فراهم می کند. عناصر HTML با تگ ها مشخص می شوند که با استفاده از براکت های زاویه نوشته می شوند. تگ هایی مثل <img /> و <input /> محتوا را مستقیما به داخل صفحه وارد می کنند. تگ های دیگری مانند <p>…</p> محتوا را دربرمی گیرند و اطلاعاتی درباره متن سند ارائه می دهند که ممکن است داخلشان تگ های دیگری هم داشته باشند. مرورگرها، تگ های HTML را نشان نمی دهند، بلکه بوسیله آنها محتوای صفحه را تفسیر می کنند.
HTML می تواند اسکریپت هایی که به زبان های دیگر مانند JavaScript نوشته شده اند را در خود جای دهد که روی رفتار صفحات وب HTML تاثیر می گذارد. HTML همچنین می تواند مرورگر را به Cascading Style Sheets (CSS) ارجاع دهد تا ظاهر و سبک متن و دیگر عناصر را تعیین کند. World Wide Web Consortium (W3C) که حفظ کننده استانداردهای HTML و CSS است، از سال 1997 استفاده از CSS را به جای HTML توصیه کرده است.
تاریخچه اچ تی ام ال – HTML
 توسعه
توسعه
در سال 1980، تیم برنرز لی، یک فیزیکدان که در آن زمان در شرکت CERN یک پیمانکار بود، سیستم ENQUIRE را نمونه سازی کرده و پیشنهاد داد، سیستمی برای محققان CERN تا از اسنادشان استفاده کرده و آنها را به اشتراک بگذارند. در سال 1989، برنرز لی یک یک یادداشت نوشت و پیشنهاد یک سیستم فرامتنی مبتنی بر اینترنت را داد. برنرز لی در سال 1990 مشخص کرد و نرم افزار مرورگر و سرور آن را نوشت. در آن سال، برنرز لی و مهندس سیستم های داده CERN به نام رابرت کایلیو به اتفاق هم درخواست تامین بودجه کردند، اما این پروژه بطور رسمی توسط CERN پذیرفته نشد. وی در یادداشت های شخصی خود از سال 1990 بسیاری از زمینه هایی که می توان از Hypertext استفاده کرد را نوشت و در ابتدا یک دانشنامه نوشت.
اولین توضیحات HTML که بطور عمومی در دسترس قرار گرفت سندی به نام “تگ های HTML” بود که اولین بار توسط تیم برنرز لی در اواخر سال 1991 در اینترنت به آن اشاره شد. در آن 18 عنصر توصیف شد که شامل طراحی اولیه و ساده HTML بودند. به جز تگ Hyperlink، این تگ ها به از SGMLguid الهام گرفته شده بودند، یک سند مبتنی بر زبان نشانه گذاری عمومی استاندارد (SGML) داخلی در شرکت CERN. یازده تا از این عناصر هنوز در HTML 4 موجود هستند.
 HTML یک زبان نشانه گذاری است که مرورگرهای وب از آن برای تفسیر و تبدیل متن، تصاویر، و دیگر عناصر به صفحات وب بصری یا شنیداری استفاده می کنند. خصوصیات پیش فرض هر یک از آیتم های زبان نشانه گذاری HTML در مرورگر مشخص شده است و این خصوصیات را می توان با استفاده از CSS توسط طراح صفحه وب تغییر داد یا اصلاح کرد. بسیاری از عناصر متنی در گزارش فنی ISO 1988 به نام “تکنیک های TR 9537 برای استفاده از SGML” موجود است که شامل ویژگی های زبان های اولیه قالب بندی متن است، مانند آنهایی که توسط دستور RUNOFF استفاده می شوند که در اوایل دهه 1960 برای سیستم عامل CTSS (Compatible Time-Sharing System) توسعه داده شد: این فرمان های قالب بندی از فرمان های استفاده شده توسط حروف چین ها برای قالب بندی دستی اسناد گرفته شده بودند. هرچند مفهوم نشانه گذاری عمومی SGML براساس عناصر است (دامنه های مشروح تودرتو دارای خصوصیات) نه اثرات چاپی و همچنین ساختار و نشانه گذاری از هم جدا شده اند؛ HTML به تدریج به همراه CSS در این مسیر حرکت کرد.
HTML یک زبان نشانه گذاری است که مرورگرهای وب از آن برای تفسیر و تبدیل متن، تصاویر، و دیگر عناصر به صفحات وب بصری یا شنیداری استفاده می کنند. خصوصیات پیش فرض هر یک از آیتم های زبان نشانه گذاری HTML در مرورگر مشخص شده است و این خصوصیات را می توان با استفاده از CSS توسط طراح صفحه وب تغییر داد یا اصلاح کرد. بسیاری از عناصر متنی در گزارش فنی ISO 1988 به نام “تکنیک های TR 9537 برای استفاده از SGML” موجود است که شامل ویژگی های زبان های اولیه قالب بندی متن است، مانند آنهایی که توسط دستور RUNOFF استفاده می شوند که در اوایل دهه 1960 برای سیستم عامل CTSS (Compatible Time-Sharing System) توسعه داده شد: این فرمان های قالب بندی از فرمان های استفاده شده توسط حروف چین ها برای قالب بندی دستی اسناد گرفته شده بودند. هرچند مفهوم نشانه گذاری عمومی SGML براساس عناصر است (دامنه های مشروح تودرتو دارای خصوصیات) نه اثرات چاپی و همچنین ساختار و نشانه گذاری از هم جدا شده اند؛ HTML به تدریج به همراه CSS در این مسیر حرکت کرد.
برنرز لی HTML را برنامه ای از SGML در نظر گرفت که قبلا هم توسط نیروی کاری مهندسان اینترنتی (IETF) با انتشار اولین پیشنهاد HTML در اوایل سال 1993 به همین صورت تعریف شد: یک پیش نویس اینترنتی درباره زبان نشانه گذاری فرامتنی (HTML) توسط برنرز لی و دن کونولی که شامل تعریف نوع سند SGML برای تعریف گرامر آن بود. این پیش نویس بعد از 6 ماه منقضی شد، اما به خاطر تصدیق تگ های اختصاصی مرورگر NCSA Mosaic برای تعبیه تصاویر درون متن قابل توجه بود که نشانگر فلسفه IETF مبنی بر تکیه دادن استانداردها روی پروتکل های موفق بود. بطور مشابه، پیش نویس اینترنتی رقابتی دیو رگت به نام “HTML+ (Hypertext Markup Format)” در اواخر سال 1993، ویژگی های استاندارد از پیش تعبیه شده ای مانند جداول و فرم ها را پیشنهاد کرد.
پس از منقضی شدن پیش نویس های HTML و HTML+ در اوایل سال 1994، تیم IETF یک گروه کاری HTML را ایجاد کرد که در سال 1995 “HTML 2.0” را کامل کرد، اولین مشخصات HTML که به عنوان یک استاندارد ساخته شد تا پیاده سازی های آینده بر مبنای آن انجام شوند.
توسعه های بعدی تحت نظارت IETF به خاطر منافع رقابتی متوقف شد. از سال 1996، مشخصات HTML با یک مبلغی از طرف فروشندگان تجاری نرم افزار توسط World Wide Web Consortium (W3C) حفظ شد. البته در سال 2000، HTML همچنین تبدیل به یک استاندارد بین المللی (ISO/IEC 15445:2000) شد. HTML 4.1 در اواخر سال 1999 عرضه شد و لیست اشتباهات آن هم تا سال 2001 ارائه شد. در سال 2004، توسعه HTML 5 در گروه کاری تکنولوژی برنامه فرامتنی وب (WHATWG) آغاز شد که به همراه W3C تبدیل به یک استاندارد قابل تحویل مشترک شد و در 28 اکتبر سال 2014 تکمیل و استانداردسازی شد.
زبان نشانه گذاری اچ تی ام ال
زبان نشانه گذاری HTML شامل متشکل از چندین مولفه اصلی است که شامل تگ ها (و خصوصیات آنها)، نوع داده مبتنی بر حروف، منابع حروف و منابع هویتی است. تگ های HTML عموما به صورت دوتایی استفاده می شوند، مانند <h1> و </h1>، گرچه برخی از آنها نمایانگر عناصر خالی هستند و از اینرو تکی هستند، مثلا <img>. اولین تگ جفتی تگ Start و آخرین آن تگ End است (به آنها تگ های آغاز و پایان هم گفته می شود).
یک مولفه مهم دیگر، اعلامیه نوع سند HTML است که طریقه رندر Standard Mode را فراخوانی می کند.
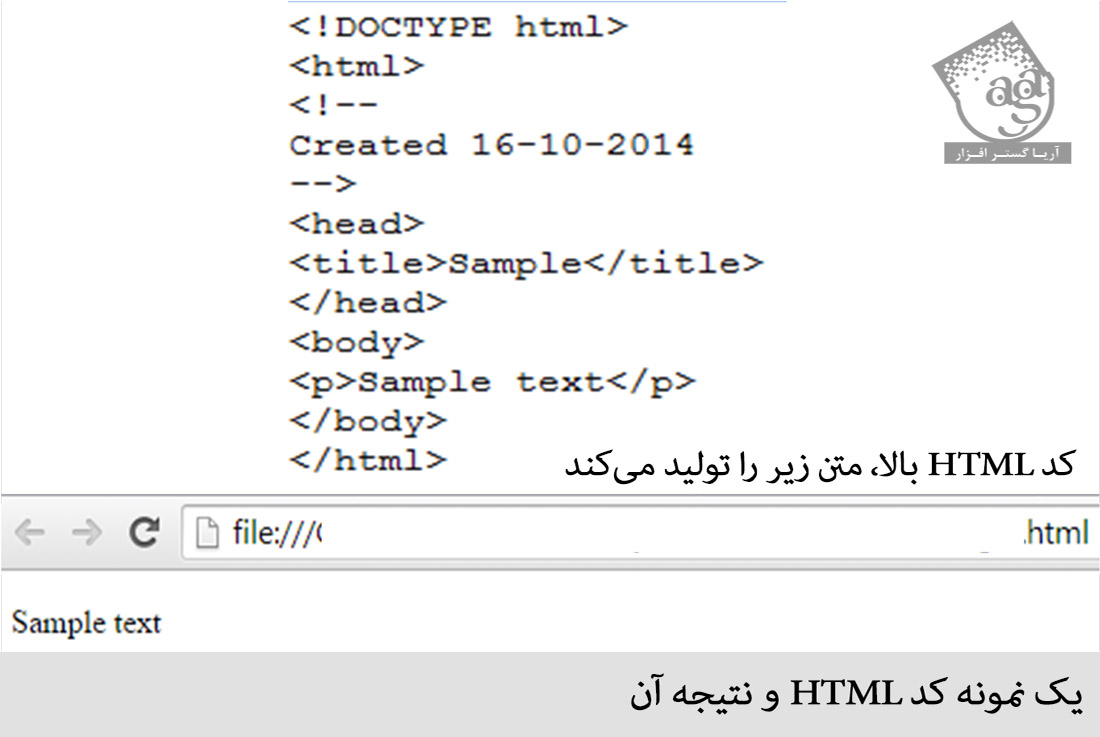
نمونه زیر یک مثال از برنامه کلاسیک Hello World است ، یک تست رایج که برای مقایسه زبان های برنامه نیسی، زبان های اسکریپت نویسی و زبان های نشانه گذاری مورد استفاده قرار می گیرد. این مثال با استفاده از 9 خط کد نوشته شده است.
<!DOCTYPE html> <html> <head> <title>This is a title</title> </head> <body> <p>Hello world!</p> </body> </html>
متن بین <html> و </html> صفحه وب را توصیف می کند و متن بین <body> و </body>، محتوای قابل رویت صفحه است. متن نشانه گذاری “<title>This is a title</title>”، عنوان صفحه مرورگر را تعیین می کند.
اعلامیه نوع سند <!DOCTYPE html> برای HTML 5 است. اگر اعلامیه شامل نشده باشد، بسیاری از مرورگرها به حالت quirks mode برای رندر کردن صفحات رجوع می کنند.
 عناصر اچ تی ام ال
عناصر اچ تی ام ال
 عناصر اچ تی ام ال
عناصر اچ تی ام الاسناد HTML به یک ساختار عناصر HTML تودرتو اشاره دارند. اینها در اسناد با تگ های HTML مشخص می شوند که در براکت های زاویه قرار دارند. مانند: <p>
در حالت ساده و معمولی، طول یک عنصر با یک جفت تگ مشخص می شود: یک تگ آغاز <p> و تگ پایانی </p>. محتوای متنی عنصر در صورت وجود داشتن در بین این دو تگ قرار می گیرد.
تگ ها همچنین ممکن است نشانه گذاری های تگ دیگری را بین Start و End دربربگیرند، مانند ترکیبی از تگ ها و متن ها. این نمایانگر عناصر (تودرتو) بیشتر به عنوان فرزند عناصر والد است.
تگ آغاز همچنین ممکن است شامل خصیصه هایی داخل تگ باشد. اینها شامل اطلاعات دیگری هستند، مانند شناسه هایی برای انتخاب در داخل سند، شناسه هایی برای متصل کردن اطلاعات استایل به نمایش سند و برای برخی تگ ها مانند <img> که برای تعبیه تصاویر استفاده می شود، مرجعی به منبع تصویر.
برخی از عناصر مانند جداساز خط <br> اجازه تعبیه هیچ محتوایی را نمی دهند، چه متن و چه تگ های دیگر. اینها تنها نیازمند یک تگ خالی (مااند تگ آغاز) هستند و از تگ پایانی استفاده نمی کنند.
بسیاری از تگ ها، مخصوصا تگ پایانی برای عنصر رایج پاراگراف <p>، اختیاری هستند. یک مرورگر HTML یا دیگر واسطه ها می توانند از محتوا و قوانین ساختاری تعریف شده توسط استاندارد HTML، می توانند بسته شدن انتهای یک عنصر را تشخیص دهند. این قوانین پیچیده هستند و اکثر کدنویس های HTML آنها را درک نمی کنند.
بنابراین شکل کلی یک عنصر HTML به این صورت است: <tag attribute1=”value1″ attribute2=”value2″>”content”</tag>. برخی از عناصر HTML به عنوان عناصر خالی تعریف می شوند و به صورت <tag attribute1=”value1″ attribute2=”value2″> هستند. عناصر خالی ممکن است هیچ محتوایی نداشته باشند، برای مثال، تگ <br> یا تگ درون خطی <img>. نام یک عنصر HTML نامی است که در تگ استفاده شده است. توجه کنید که قبل از نام تگ پایانی یک کاراکتر اسلش “/” می آید و در عناصر خالی، تگ های پایانی نه ضروری هستند و نه مجاز. اگر به خصیصه ها اشاره نشود، در هر مورد از مقادیر پیش فرض استفاده می شود.
مثال های عناصر
سربرگ یک سند HTML: <head>…</head>. عنوان در تگ Head قرار می گیرد. برای مثال:
<head> <title>The Title</title> </head>
عناوین: عناوین HTML با تگ های <h1> تا <h6> مشخص می شوند:
<h1>Heading level 1</h1> <h2>Heading level 2</h2> <h3>Heading level 3</h3> <h4>Heading level 4</h4> <h5>Heading level 5</h5> <h6>Heading level 6</h6>
پاراگراف ها:
<p>Paragraph 1</p> <p>Paragraph 2</p>
جداکننده خطوط: <br>. تفاوت بین <br> و <p> این است که <br> بدون تغییر دادن ساختار معنایی صفحه، خط را جدا می کند، درحالیکه <p> صفحه را به پاراگراف های مختلف تقسیم می کند. همچنین توجه کنید که <br> یک عنصر خالی است و با اینکه ممکن است خصیصه داشته باشد، اما نمی تواند محتوا داشته باشد و ممکن است تگ پایانی هم نداشته باشد.
<p>This <br> is a paragraph <br> with <br> line breaks</p>
این یک لینک در HTML است. برای ایجاد لینک از تگ <a> استفاده می شود. خصیصه href=، آدرس URL لینک را در خود جای می دهد.
<a href="https://www.wikipedia.org/">A link to Wikipedia!</a>
توضیحات:
<!-- This is a comment -->
توضیحات می توانند به درک نشانه گذاری کمک کنند و در صفحه وب نمایش داده نمی شوند.
چندین نوع نشانه گذاری در HTML استفاده می شود:
نشانه گذاری ساختاری که هدف متن را مشخص می کند
برای مثال، <h2>Golf</h2> کلمه Golf را به عنوان یک عنوان سطح دوم مشخص می کند. نشانه گذاری ساختاری دلالت بر نوع خاصی از رندر شدن ندارد، اما اکثر مرورگرهای وب دارای استایل های پیش فرض برای قالب بندی عناصر هستند. محتوا را می توان با استفاده از Cascading Style Sheets (CSS) بیشتر قالب بندی کرد.
نشانه گذاری نمایشی نمایانگر ظاهر یک متن، صرف نظر از هدف آن است
برای مثال، <b>boldface</b> نشان می دهد که دستگاه های خروجی تصویری باید کلمه Boldface را به صورت پررنگ یا Bold نشان دهند، اما توضیحی نمی دهد که کدام دستگاه هایی که توانایی این کار را ندارند (مانند دستگاه های شنیداری که متن را به صورت صوتی می خوانند) باید آن را انجام دهند. در هر دو مورد <b>bold</b> و <i>italic</i>، عناصر دیگری وجود دارند که ممکن است رندرهای تصویری یکسانی داشته باشند، اما طبیعت آنها معنایی تر است، مانند <strong>strong text</strong> و <em>emphasised text</em>. راحت تر می توان دید که واسطه کاربری شنیداری چطوری باید دو عنصر آخری را تفسیر کند. البته اینها با همتاهای نمایشی خود برابر نیستند: مثلا برای یک واسطه تصویرخوان مناسب نیست که اسم یک کتاب را تاکید کند، اما در تصویر، چنین اسمی باید Italic باشد. بیشتر عناصر نشانه گذاری نمایشی در HTML 4.0 به خاطر استفاده از CSS برای قالب بندی، منسوخ شده اند.
نشانه گذاری فرامتنی قسمت هایی از یک سند را تبدیل به لینک هایی به دیگر اسناد می کند
یک عنصر Anchor یک hyperlink در سند ایجاد می کند و خصیصه href آن URL لینک هدف را مشخص می کند. برای مثال، نشانه گذاری <a href=”http://www.google.com/”>Wikipedia</a>، کلمه Wikipedia را به عنوان یک Hyperlink رندر می کند. برای رندر کردن یک تصویر به عنوان Hyperlink، یک عنصر img به عنوان محتوا داخل عنصر a وارد می شود. Img هم مانند br یک عنصر خالی دارای خصیصه است، اما محتوا یا تگ پایانی ندارد.
<a href="http://example.org"><img src="image.gif" alt="descriptive text" width="50" height="50" border="0"></a>.
خصیصه ها
اکثر خصیصه های یک عنصر، زوج های Name-Value هستند که توسط یک = از هم جدا شده اند و در داخل تگ آغازی یک عنصر بعد از نام عنصر نوشته می شوند. مقدار را می توان داخل علامت apostrophe یا نقل قول قرار داد، گرچه مقادیری که حاوی کاراکتراهای خاصی هستند را می توان در HTML بدون بدون علامت گذاشت (اما نه XHTML). بدون علامت گذاشتن مقادیر خصیصه ها کاری ناامن تلقی می شود. برعکس خصیصه های زوج Name-Value، برخی خصیصه ها هستند که تنها با حضور در تگ آغاز عنصر، روی عنصر تاثیر می گذارند، مانند خصیصه ismap برای عنصر img.
چند خصیصه مشترک برای عناصر مختلف وجود دارد:
– خصیصه id یک شناسه منحصربفرد در سراسر سند برای یک عنصر فراهم می کند. از این برای شناسایی عنصر استفاده می شود تا stylesheetها بتوانند خصوصیات نمایشی آن را تغییر دهند و اسکریپت ممکن است محتوا یا نمایش آن را تغییر داده، متحرک کرده یا حذف کند. این خصیصه که به URL صفحه اضافه می شود، یک شناسه منحصربفرد عمومی، معمولا یک زیربخش از صفحه، برای عنصر فراهم می کند. برای مثال، خصیصه های ID در http://en.wikipedia.org/wiki/HTML#Attributes.
– خصیصه class روشی برای طبقه بندی عناصر مشابه فراهم می کند. از این می توان برای اهداف معنایی یا نمایشی استفاده کرد. برای مثال، یک سند HTML ممکن است بطور معنایی از تعیین کننده class=”notation” استفاده کند تا نشان دهد که تمام عناصر دارای این مقدار class، تابع متن اصلی سند هستند. در نمایش، چنین عناصری ممکن است با هم جمع شوند و به جای ظاهر شدن در جایی که در کد HTML قرار دارند، به عنوان پاصفحه در صفحه نشان داده شوند. خصیصه های class به صورت معنایی در میکروفرمت ها استفاده می شوند. چندین مقدار class را می توان مشخص کرد، برای مثال، class=”notation important” عنصر را در classهای Notation و important قرار می دهد.
– یک نویسنده می تواند از خصیصه style برای تخصیص دادن مشخصات ظاهری به یک عنصر استفاده کند. بهتر است که از خصیصه های id یا class یک عنصر برای انتخاب عنصر در یک stylesheet استفاده شود، گرچه گاهی اوقات ممکن است برای قالب بندی ساده، خاص یا تک منظوره، کار دشواری باشد.
– از خصیصه title برای متصل کردن توضیحات زیرمتنی به یک عنصر استفاده می شود. در اکثر مرورگرها این خصیصه به عنوان یک tooltip نمایش داده می شود.
– خصیصه lang، زبان طبیعی محتوای عنصر را شناسایی می کند که ممکن است از بقیه قسمت های سند متفاوت باشد. برای مثال، در یک سند با زبان انگلیسی:
<p>Oh well, <span lang=”fr”>c’est la vie</span>, as they say in France.</p>
از عنصر کوتاه نویسی abbr می توان برای نشان دادن برخی از این خصیصه ها استفاده کرد:
<abbr id="anId" class="jargon" style="color:purple;" title="Hypertext Markup Language">HTML</abbr>
این مثال به عنوان یک HTML نشان داده شده است. در اکثر مرورگرها با بردن نشانگر موس روی کلمه مخفف، باید متن Hypertext Markup Language نمایش داده شود.
اکثر عناصر از خصیصه زبانی dir برای مشخص کردن جهت متن استفاده می کنند، مانند rtl برای متن راست به چپ، مثلا برای زبان های عربی، فارسی و عبری.
منابع کاراکتر و کاراکتر خاص در HTML
بعد از ورژن 4، HTML یک مرجع از 252 کاراکتر و کاراکتر خاص و مجموعه ای از 1114050 مرجع کاراکتر عددی تعیین کرده است که هر دو تای آنها اجازه می دهند کاراکترهای انفرادی به جای نوشته شدن بطور لفظی، با نشانه گذاری های ساده نوشته شوند. یک کاراکتر لفظی و همتای Markup آن با هم برابر در نظر گرفته می شوند و بطور یکسان رندر می شوند.
قابلیت escape کردن کاراکترها به این صورت به کاراکترهای < و > اجازه می دهد (وقتی به صورت < و & نوشته شوند) به جای نشانه گذاری به عنوان داده کاراکتری تفسیر شوند. برای مثال، یک کاراکتر لفظی < معمولا نشان دهنده شروع یک تگ است و & معمولا نشانگر شروع یک مرجع کاراکتر خاص یا مرجع کاراکتر عددی است. نوشتن آن به صورت & یا & یا & به & اجازه می دهد در محتوای یک عنصر یا در مقدار یک خصیصه نوشته شود. علامت نقل قول (“) هم اگر برای نقل قول کردن مقدار یک خصیصه استفاده نشود، باید به صورت " یا ” یا ” نوشته شود تا خود آن در مقدار خصیصه نشان داده شود. به همین صورت زمانی که کاراکتر آپاستروف (‘) برای نقل قول کردن یک مقدار خصیصه استفاده نشود، باید به صورت ‘ یا ‘، escape شود (یا ' در اسناد HTML 5 یا XHTML) تا در خود مقدار خصیصه وارد شود. اگر نویسندگان سند نیاز به escape کردن چنین کاراکترهایی را نادیده بگیرند، برخی از مرورگرها سعی می کنند با از محتوا، مقصود آنها را متوجه شوند. نتیجه اش باز هم یک نشانه گذاری نامعتبر می شود که باعث می شود سند برای دیگر مرورگرها و دیگر واسطه های کاربری که مثلا از سند برای اهداف جستجو و فهرست بندی استفاده می کنند، در دسترس نباشد.
Escape کردن همچنین به کاراکترهایی که به راحتی تایپ نمی شوند یا در رمزگذاری کاراکتر سند موجود نیستند اجازه می دهد تا در محتوای عنصر و خصیصه جایگزین شوند. برای مثال، علامت اکسان e (é) که عموما تنها در کیبوردهای اروپای غربی و امریکای جنوبی یافت می شود را می توان در هر سند HTMLی به صورت مرجع کاراکتر خاص é یا به صورت کاراکتر عددی é یا é نوشت، کاراکترهایی که در تمام کیبوردها و موجود هستند و در تمام رمزنگاری های کاراکتری پشتیبانی می شوند. رمزنگاری های کاراکترهای یونیکد مانند UTF-8 با تمام مرورگرهای مدرن سازگار هستند و اجازه دسترسی مستقیم به تقریبا تمام کاراکترهای سیستم های نوشتاری دنیا را می دهند.
انواع داده HTML
HTML چند نوع داده را برای محتوای عنصر، مانند داده اسکریپت و داده Stylesheet تعریف می کند و انواع بسیار زیادی برای مقادیر خصیصه شامل IDها، اسامی، URIها، اعداد، واحدهای طول، زبان ها، توصیف گرهای رسانه ای، رنگ ها، رمزنگاری های کاراکتر، تاریخ و زمان و غیره. تمام این انواع داده ها، انواع خاصی از داده کاراکتری هستند.
اعلامیه نوع سند
اسناد HTML باید با یک اعلامیه نوع سند آغاز شوند (که عموما به آن doctype گفته می شود). Doctype در مرورگرها به تعریف حالت رندر کمک می کند، مخصوصا برای استفاده کردن یا نکردن از Quirks Mode.
هدف اصلی doctype، تجزیه کردن و تایید اعتبار اسناد HTML توسط ابزارهای SGML طبق تعریف نوع سند (DTD) است. DTD که doctype به آن اشاره دارد، شامل یک گرامر قابل خواندن توسط دستگاه است که محتوای مجاز و غیرمجاز سند را با چنینی DTD تایید می کند. مرورگرها از سوی دیگر از HTML به عنوان برنامه ای از SGML استفاده نمی کنند و در نتیجه، DTD را نمی خوانند.
HTML 5 یک DTD تعریف نمی کند، در نتیجه اعلامیه نوع سند در HTML 5 ساده تر و کوتاه تر است.
<!DOCTYPE html>
یک مثال از نوع سند HTML 4:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
این اعلامیه DTD را برای ورژن Strict HTML 4 مرجع قرار می دهد. اعتبارسنج های مبتنی بر SGML، DTD را می خوانند تا بطور صحیح سند را تجزیه کرده و عمل اعتبارسنجی را انجام دهند. در مرورگرهای مدرن، یک doctype معتبر، Standards Mode را به جای Quirks Mode فعال می کند.
به علاوه، HTML 4، DTDهای Transitional و Frameset را فراهم می کند که در زیر توضیح داده شده است. نوع Transitional جامع ترین نوع است و از تگ های کنونی و همچنین تگ های قدیمی تر یا منسوخ شده با DTD Strict استفاده می کند که تگ های منسوخ شده را حذف می کند. Frameset تمام تگ های لازم برای ایجاد قاب های درون صفحه را به همراه تگ های نوع Transitional دارد.
اچ تی ام ال معنایی ( HTML Semantics )
HTML معنایی روشی از نوشتن HTML است که بیشتر روی معنی اطلاعات رمزنگاری شده تاکید دارد تا نمایش (ظاهر) آن. HTML از زمان آغاز شامل نماشنه گذاری معنایی بوده است، اما همچنین نشانه گذاری های نمایشی هم اضافه کرده است، مانند تگ های <font>، <i> و <center>. همچنین تگ های span و div هم وجود دارند که از نظر معنایی خنثی هستند. از اواخر دهه 1990 که Cascading Style Sheet در حال ورود به اکثر مرورگرها بود، به خاطر جدایی ظاهر و محتوا، نویسندگان وب به عدم استفاده از نشانه گذاری HTML نمایشی ترغیب می شدند.
در گفتگوی وب معنایی در سال 2001، تیم برنرز لی و دیگران شیوه هایی را مثال زدند که طبق آنها در آینده ممکن است عامل های نرم افزاری هوشمند بطور خودکار وب را جستجو کرده و حقایق منتشر شده قبلی و نامرتبط را پیدا کرده و به خاطر راحتی کاربران، آنها را به هم مرتبط کنند. چنین عامل هایی حتی الان هم متداول نیستند، اما برخی از ایده های وب 2، صفحات ترکیبی و وبسایت های مقایسه قیمت دارند به این امر نزدیک می شوند. تفاوت اصلی بین این برنامه های وب دوگانه و عامل های معنایی برنرز لی این است که تجمع و پیوندزنی اطلاعات معمولا توسط توسعه دهندگان وب طراحی می شود که مکان های وب و معناشناسی API داده مورد نظرشان برای ترکیب و مقایسه کردن را می شناسند. یک نوع عامل وب مهم که بطور خودکار صفحات را جستجو کرده و می خواند، بدون اینکه از قبل بداند چه چیزی را پیدا خواهد کرد، خزنده وب یا عنکبوت موتور جستجو نام دارد. این عاملان نرم افزاری وابسته به شفافیت معنایی صفحات وب هستند، زیرا از تکنیک ها و الگوریتم های متنوعی برای خواندن و فهرست کردن میلیون ها صفحه وب در روز استفاده می کنند و به کاربران وب تسهیلات جستجویی را عرضه می کنند که بدون آنها، فایده شبکه جهانی وب بشدت کاهش پیدا می کند.
برای اینکه عنکبوت موتور جستجو بتواند اهمیت متونی که در اسناد HTML پیدا می کند را درک کند و همچنین برای کسانی که وبسایت های ترکیبی یا دوگانه می سازند و برای عامل های خودکار بیشتر، ساختارهای معنایی موجود در HTML باید بطور وسیع و یکنواخت اعمال شوند تا معنی متون منتشر شده را درک کنند.
تگ های نشانه گذاری نمایشی در پیشنهادات HTML و XHTML کنونی منسوخ شده اند و در HTML 5 ممنوع هستند.
HTML معنایی خوب، همچنین دسترسی به اسناد وب را بهبود می دهد. برای مثال، وقتی یک مرورگر تصویر خوان یا شنیداری بتواند بطور صحیح ساختار یک سند را مشخص کند، دیگر وقت کاربر نابینا را با خواندن اطلعات تکراری یا بی ربط هدر نمی دهد.

تحویل
اسناد HTML را می توان مانند تمام فایل های کامپیوتری دیگر تحویل داد، البته اغلب اوقات توسط HTTP از یک سرور وب یا توسط ایمیل تحویل داده می شوند.
HTTP
شبکه جهانی وب در درجه اول از اسناد HTML تشکیل شده است که از سرورهای وب به مرورگرهای وبی که از پروتکل انتقال فرامتنی (HTTP) استفاده می کنند، فرستاده می شود. هرچند، به غیر از HTML، از HTTP برای نشان دادن تصاویر، صدا و دیگر محتواها هم استفاده می شود. برای اجازه دادن به مرورگر وب تا بداند چطوری با هر یک اسناد دریافتی کار کند، اطلاعات دیگری هم به همراه سند ارسال می شوند. این meta data عموما شامل نوع MIME (مانند متن، HTML یا برنامه / XHTML + XML) و رمزنگاری کاراکتر است.
در مرورگرهای مدرن، نوع MIME که با سند HTML ارسال می شود ممکن است روی طریقه تفسیر شدن اولیه سند تاثیر بگذارد. انتظار می رود سندی که به همراه نوع XHTML MIME ارسال می شود XML باشد. ارورهای نحوی ممکن است باعث شوند مرورگر موفق به رندر کردن آن نشود. همان سند اگر با نوع HTML MIME ارسال شود ممکن است به خوبی نمایش داده شود، زیرا برخی مرورگرها با HTML بیشتر سازگار هستند.
در توصیه نامه W3C اشاره شده است که اسناد XHTML 1.0 که از دستورالعمل های ذکر شده در ضمیمه C توصیه نامه پیروی می کنند، می توانند هر یک از انواع MIME را داشته باشند. XHTML 1.1 همچنین اشاره می کند که اسناد XHTML 1.1 باید یکی از انوع MIME محسوب شوند.
HTML e-mail
اکثر مشترکان ایمیل گرافیکی اجازه استفاده از یک زیرمجموعه HTML (که اغلب به خوبی تعریف نشده است) را می دهند تا نشانه گذایر های قالب بندی و معنایی ارائه کنند که در متن خالی در دسترس نیست. این می تواند شامل اطلاعات تایپوگرافی مانند عناوین رنگی، متن تاکید یا نقل قول شده و تصاویر و نمودارهای درون متنی باشد. بسیاری از چنین مشترکانی هم دارای ویرایشگر GUI برای ایجاد پیام های ایمیل HTML هستند و هم یک موتور رندر برای نمایش دادن آنها. به خاطر مشکلات سازگاری، استفاده از HTML در ایمیل توسط بعضی ها مورد انتقاد قرار گرفته است، زیرا به دلیل مشکلات دسترسی برای افراد نابینا یا کم بینا و اینکه ممکن است فیلترهای اسپم را اشتباه بگیرد و اینکه اندازه پیام بزرگتر از متن خالی است، می تواند به مخفی کردن حملات فیشینگ کمک کند.
 قوانین نامگذاری
قوانین نامگذاری
 قوانین نامگذاری
قوانین نامگذاریرایج ترین پسوند فایل برای فایل های حاوی HTML، پسوند .html است. کوتاه شده آن .hml است که به این دلیل ایجاد شد که برخی از سیستم های عامل و سیستم های فایلی اولیه مانند DOS و محدودیت های ساختار داده های FAT، پسوند فایل ها را به سه حرف محدود می کردند.
برنامه HTML
یک برنامه HTML (HTA، با پسوند .hta)، یک برنامه ویندوزی است که از HTML و Dynamic HTML در مرورگر استفاده می کند تا رابط کاربری گرافیکی برنامه را فراهم کند. یک فایل HTML معمولی توسط مدل امنیتی موجود در امنیت مرورگر وب محدود می شود و تنها با سرورهای وب ارتباط برقرار کرده و تنها آیتم های صفحه وب و کوکی های سایت را دستکاری می کند. یک HTA به عنوان یک برنامه کاملا مطمئن اجرا می شود و از اینرو دارای مزیت های بیشتری است، مانند ایجاد، ویرایش و حذف فایل ها و آیتم های رجیستری ویندوز. HTAها به دلیل اینکه خارج از مدل امنیتی مرورگر کار می کنند، نمی توانند توسط HTTP اجرا شوند، بلکه باید دانلود شوند (مانند یک فایل EXE) و از سیستم فایل محلی اجرا شوند.
انواع HTML 4
HTML و پروتکل های مربوط به آن از همان ابتدا با سرعت نسبتا بالایی مقبولیت پیدا کردند. هرچند هیچ استاندارد واضحی در سال های اولیه وجود نداشت. گرچه سازندگان آن، HTML را یک زبان معنایی فاقد جزئیات نمایشی می دانستند، مواد استفاده کاربردی باعث ایجاد بسیاری از عناصر و خصیصه های نمایشی در این زبان شد که عامل این کار عموما فروشندگان مختلف مرورگر بودند. آخرین استانداردهای HTML نمایانگر تلاش هایی برای غلبه بر توسعه بی نظم این زبان و ایجاد یک مبنای منطقی برای ساخت اسناد بامعنی و به خوبی معرفی شده است. برای بازگرداندن HTML به نقش پیشین آن به عنوان یک زبان معنایی، W3C زبان های قالب بندی مانند CSS و XSL را توسعه داده است تا مسئولیت نمایش را به عهده بگیرند. در همین راستا، خصوصیات HTML به تدریج از عناصر نمایشی خارج شده است.
دو محور وجود دارد که باعث تمایز بین انواع HTML می شوند که در حال حاضر شامل: HTML مبتنی بر SGML علیه HTML مبتنی بر XML (یا همان XHTML) در یک محور و HTML Strict علیه Transitional (آزاد) علیه Frameset در محور دیگر.
HTML مبتنی بر SGML علیه HTML مبتنی بر XML
 یکی از تفاوت های آخرین خصوصیات HTML مربوط به وجه تمایز بین خصوصیات مبتنی بر SGML و خصوصیات مبتنی بر XML است. خصوصیات مبتنی بر XML معمولا XHTML نامیده می شود تا بطور واضح تری از تعریف سنتی آن تمایز پیدا کند. هرچند، نام عنصر ریشه ای آن همچنان html است، حتی HTML تعیین شده توسط XHTML. W3C در نظر داشت که XHTML 1.0 با HTML 4.01 یکسان باشد، به جز در مواردی که محدودیت های XML نسبت به SGML نیاز به راه حل دارد. به دلیل اینکه XHTML و HTML بطور نزدیکی با هم ارتباط دارند، گاهی اوقات بطور موازی با هم مستند می شوند. در چنین شرایطی، برخی نویسندگان این دو نام را به صورت (X)HTML و X(HTML) تلفیق می کنند.
یکی از تفاوت های آخرین خصوصیات HTML مربوط به وجه تمایز بین خصوصیات مبتنی بر SGML و خصوصیات مبتنی بر XML است. خصوصیات مبتنی بر XML معمولا XHTML نامیده می شود تا بطور واضح تری از تعریف سنتی آن تمایز پیدا کند. هرچند، نام عنصر ریشه ای آن همچنان html است، حتی HTML تعیین شده توسط XHTML. W3C در نظر داشت که XHTML 1.0 با HTML 4.01 یکسان باشد، به جز در مواردی که محدودیت های XML نسبت به SGML نیاز به راه حل دارد. به دلیل اینکه XHTML و HTML بطور نزدیکی با هم ارتباط دارند، گاهی اوقات بطور موازی با هم مستند می شوند. در چنین شرایطی، برخی نویسندگان این دو نام را به صورت (X)HTML و X(HTML) تلفیق می کنند.
XHTML 1.0 هم مانند HTML 4.01 دارای سه مشخصات فرعی است: Strict، Transitional و Frameset.
جدای از اعلامیه های آغازی متفاوت برای اسناد، تفاوت بین یک سند HTML 4.01 و XHTML 1.0 در هر یک از DTDهای مربوطه عموما نحوی است. قاعده اصلی HTML اجازه بسیاری از میانبرها را می دهد که XHTML نمی دهد، مانند عناصری با تگ های آغاز و پایان اختیاری و حتی عناصر خالی که نباید دارای تگ پایانی باشند. برعکس، XHTML نیازمند این است که تمام عناصر دارای تگ های آغاز و پایان باشند. هرچند XHTML همچنین یک میانبر جدید را معرفی می کند: یک تگ XHTML را می توان با یک تگ آغاز کرده و خاتمه داد. برای این کار باید یک اسلش قبل از انتهای تگ قرار داده شود، مانند <br/>. معرفی این میانبر که در اعلامیه SGML برای HTML 4.01 استفاده نشده است، ممکن است نرم افزارهای قدیمی تر که با این شیوه آشنایی ندارند را گیج کند. برای حل این مشکل می توان یک فاصله قبل از بستن تگ گذاشت، مانند <br />.
برای درک اختلافات جزئی میان HTML و XHTML، یک سند XHTML 1.0 معتبر و مناسب که به ضمیمه C پایبند است را در نظر بگیرید که به یک سند معتبر HTML 4.01 تبدیل می شود. انجام این تبدیل، نیازمند مراحل زیر است:
1. زبان یک عنصر به جای خصیصه xml:lang در XHTML، باید با یک خصیصه lang تعیین شود. XHTML از زبان درونی XML برای تعریف کردن خصیصه های کاربردی استفاده می کند.
2. حذف کردن فضای نام XML. HTML هیچ امکاناتی برای فضای نام ندارد.
3. تغییر اعلامیه نوع سند از XHTML 1.0 به HTML 4.01.
4. حذف کردن اعلامیه XML در صورت وجود داشتن، (عموما به این صورت است: <?xml version=”1.0″ encoding=”utf-8″?>).
5. حصول اطمینان از اینکه نوع MIME سند روی text/html تنظیم شده است. هم برای HTML و هم XHTML، این از سربرگ content-type از HTTP بدست می آید که توسط سرور ارسال شده است.
6. تغییر دادن قاعده عنصر خالی XML به یک عنصر خالی استایل HTML (<br/> به <br>).
اینها تغییرات اصلی لازم برای برگرداندن یک سند از XHTML 1.0 به HTML 4.01 هستند. برگرداندن از HTML به XHTML نیز نیازمند اضافه کردن تمام تگ های آغازی و پایانی حذف شده است. چه برای کدنویسی در HTML یا XHTML، بهتر است که همیشه تگ های اختیاری را در سند HTML وارد کنیم تا اینکه بخواهیم به یاد بیاوریم که کدام تگ ها می توانند حذف شوند.
یک سند XHTML به خوبی شکل گرفته به تمام ضروریات نحوی XML پایبند است. یک سند معتبر، به خصوصیات محتوایی برای XHTML که ساختار سند را تعیین می کند، پایبند است.
W3C برای جابه جایی راحت بین HTML و XHTML، یک سری روش پیشنهاد می کند. مراحل زیر تنها روی اسناد XHTML 1.0 می توانند اعمال شوند:
– شامل کردن خصیصه های xml:lang و lang به هر عنصری که زبان را اختصاص می دهد.
– استفاده از قاعده عنصر خالی تنها برای عناصری که در HTML به عنوان خالی در نظر گرفته شده اند.
– اضافه کردن یک فاصله اضافی در تگ های عنصر خالی: برای مثال، <br /> به جای <br/>.
– قرار دادن تگ های پایانی واضح برای عناصری که محتوا می پذیرند، اما خالی گذاشته شده اند (برای مثال، <div></div> به جای <div />.
– حذف کردن اعلامیه XML.
با دنبال کردن دستورالعمل های سازگاری W3C به دقت، یک عامل کاربر باید بتواند سند را همانند HTML یا XHTML تفسیر کند. برای اسنادی که XHTML 1.0 هستند و به این شکل سازگار شده اند، W3C به آنها اجازه می دهد که یا به عنوان HTML (با یک text/html از نوع MIME) یا XHTML (با یک application/xhtml+xml یا application/xml از نوع MIME) استفاده شوند. وقتی به عنوان XHTML تحویل داده شود، مرورگرها باید از یک تجزیه کننده XML استفاده کنند که بطور کامل به خصوصیات XML برای تجزیه کردن محتوای اسناد پایبند است.
Transitional علیه Strict
HTML 4 سه ورژن مختلف از زبان را تعریف کرده است: Strict، Transitional (که زمانی آزاد نامیده میشد) و Frameset. ورژن Strict برای اسناد جدید در نظر گرفته شده است و بهترین روش شناخته می شود، درحالیکه ورژن های Transitional و Frameset توسعه یافته اند تا انتقال اسنادی که با خصوصیات HTML قبلی مطابقت دارند یا با هیچ خصوصیاتی از ورژن HTML 4 مطابقت ندارند، را راحت تر کنند. ورژن های Transitional و Frameset اجازه نشانه گذاری نمایشی را می دهند که این قابلیت در ورژن Strict حذف شده است. به جای آن، استفاده از شیوه نامه های آبشاری یا همان cascading style sheets ترویج می شود تا نمایش اسناد HTML را بهبود ببخشند. به دلیل اینکه XHTML 1 تنها یک قاعده XML برای زبان تعریف شده توسط HTML 4 تعریف می کند، همین تفاوت ها شامل XHTML 1 هم می شود.
ورژن Transitional بخش های زیر از لغتنامه را می پذیرد که در ورژن Strict شامل نشده اند:
– یک مدل محتوای آزادتر
– عناصر درون خطی و متن های خالی بطور مستقیم در body، blockquote، form، noscript و noframes جایز هستند.
– عناصر مربوط به نمایش
– زیرخط (u) (منسوخ شده است. بازدیدکننده ممکن است آن را با یک Hyperlink اشتباه بگیرد)
– خط خورده (s) (توصیه نمی شود. به جایش از CSS استفاده شود)
– Center (توصیه نمی شود. به جایش از CSS استفاده شود)
– Font (توصیه نمی شود. به جایش از CSS استفاده شود)
– basefont (توصیه نمی شود. به جایش از CSS استفاده شود)
– خصیصه های مربوط به نمایش
– خصیصه های Background (توصیه نمی شود. به جایش از CSS استفاده شود) و bqcolor (توصیه نمی شود. به جایش از CSS استفاده شود) برای عنصر body (عنصر ضروری طبق W3C).
– خصیصه Align (توصیه نمی شود. به جایش از CSS استفاده شود)روی عناصر div، form، پاراگراف (p) و عنوان (h1…h6).
– خصیصه های align (توصیه نمی شود. به جایش از CSS استفاده شود)، noshade (توصیه نمی شود. به جایش از CSS استفاده شود)، size (توصیه نمی شود. به جایش از CSS استفاده شود) و width (توصیه نمی شود. به جایش از CSS استفاده شود) روی عنصر hr.
– عناصر align (توصیه نمی شود. به جایش از CSS استفاده شود)، border، vspace و hspace روی خصیصه های img و object (توجه، عنصر object تنها در Internet Explorer پشتیبانی می شود (نسبت به مرورگرهای اصلی)).
– خصیصه align (توصیه نمی شود. به جایش از CSS استفاده شود) روی عناصر legend و caption.
– خصیصه های align (توصیه نمی شود. به جایش از CSS استفاده شود) و bqcolor (توصیه نمی شود. به جایش از CSS استفاده شود) روی عنصر table.
– خصیصه های nowrap (منسوخ)، bqcolor (توصیه نمی شود. به جایش از CSS استفاده شود)، width و height روی عناصر td و th.
– خصیصه bqcolor (توصیه نمی شود. به جایش از CSS استفاده شود) روی عنصر tr.
– خصیصه clear (منسوخ) روی عنصر br.
– خصیصه compact روی عناصر d1، dir و menu.
– خصیصه های type (توصیه نمی شود. به جایش از CSS استفاده شود)، compact (توصیه نمی شود. به جایش از CSS استفاده شود) و start (توصیه نمی شود. به جایش از CSS استفاده شود) روی عناصر ol و ul.
– خصیصه های type و value روی عنصر li
– خصیصه width روی عنصر pre.
– عناصر اضافی در خصوصیات Transitional
– Menu (توصیه نمی شود. به جایش از CSS استفاده شود) list (جایگزینی ندارد، گرچه list نامرتب پیشنهاد می شود)
– Dir (توصیه نمی شود. به جایش از CSS استفاده شود) list (جایگزینی ندارد، گرچه list نامرتب پیشنهاد می شود)
– Isindex (توصیه نمی شود) عناصر نیازمند پشتیبانی از سمت سرور هستند و معمولا به اسناد سمت سرور اضافه می شوند، عناصر form و input را می توان یبه عنوان جایگزین استفاده کرد)
– Applet (توصیه نمی شود. به جایش از عنصر object استفاده شود)
– خصیصه language (منسوخ) روی عنصر script (با وجود خصیصه type، اضافی است)
– موارد مربوط به Frame
– Iframe
– noframes
– خصیصه target (در عناصر map، link و form توصیه نمی شود) روی عناصر a، image-map سمت مشتری (map)، link، form و base.
ورژن Frameset شامل تمام چیزهای ورژن Transitional است، همچنین عنصر frameset (که به جای body استفاده می شود) و عنصر frame.
Frameset علیه Transitional
به علاوه تفاوت های Transitional بالا، خصوصیات Frameset (چه XHTML 1.0 یا HTML 4.01) یک مدل محتوایی متفاوت را مشخص می کند که در آن frameset جایگزین body می شود و یا شامل عناصر frame یا nonframe به همراه Body است.
خلاصه ورژن های مشخصات
همانطور که از این لیست مشخص است، ورژن های آزاد از خصوصیات به خاطر پشتیبانی از legacy حفظ شده اند. هرچند، برخلاف تصورات غلط عموم، انتقال به XHTML به معنی حذف شدن این پشتیبانی legacy نیست. بلکه حرف X در XML نمایانگر کلمه extensible یا توسعه پذیر است و W3C دارد کل خصوصیات را مدولار می کند و آن را برای توسعه های مستقل باز می کند. موفقیت اصلی در انتقال از XHTML 1.0 به XHTML 1.1، مدولارسازی کل خصوصیات است. ورژن Strict HTML از طریق یک سری الحاق های مدولار به مبنای خصوصیات XHTML 1.1 دارد در XHTML 1.1 اعمال می شود. به همین صورت، کسی که به دنبال خصوصیات آزاد (Transitional) یا Frameset می گردد، پشتیبانی یکسانی از XHTML 1.1 را خواهد یافت (که اکثر آن در ماژول های legacy یا frame قرار دارد).فرایند مدولارسازی همچنین به ویژگی های مجزا اجازه می دهد تا در جدول زمانی خودشان توسعه پیدا کنند. برای مثال، در XHTML 1.1 انتقال به استانداردهای در حال ظهور XML مانند MathML (یک زبان ریاضی نمایشی و معنایی براساس XML) و XForms (یک تکنولوژی وب فرم جدید و بسیار پیشرفته برای جایگزین کردن فرم های HTML کنونی) سریع تر انجام می گیرد.
بطور خلاصه، خصوصیات HTML 4 اساسا در تمام پیاده سازی های HTML به یک خصوصیت انفرادی نوشته شده مبتنی بر SGML تغییر کرده اند. XHTML 1.0، این خصوصیت را به همین صورتی که هست، به خصوصیت جدید تعریف شده توسط XML وارد کرد. بعد، XHTML 1.1 از طبیعت توسعه پذیر XML استفاده می کند و کل خصوصیات را مدولار می کند. قرار بود XHTML 2.0 اولین قدم در اضافه کردن ویژگی های جدید به خصوصیات در یک رویکرد مبتنی بر بدنه استاندارد باشد.
انواع HTML 5
WHATWG HTML علیه HTML

گروه WHATWG کار خود را استاندارد HTML برای جدیدترین تکنولوژی بکار گرفته شده توسط مرورگرهای اصلی می داند، مانند Apple (Safari)، Google (Chrome)، Mozilla (Firefox)، Opera (Opera) و غیره. HTML 5 توسط گروه کاری HTML در پیروی از W3C مشخص شده است. از سال 2013 به بعد، هر دو خصوصیات مشابه هستند و عموما برگرفته شده از یکدیگر هستند. مثلا کار HTML 5 با یک پیش نویس قدیمی تر WHATWG آغاز شد و بعدها استاندارد دائمی WHATWG بر اساس پیش نویس های HTML 5 در سال 2011 قرار گرفت.
ویژگی های فرامتنی که در اچ تی ام ال وجود ندارند
HTML برخی از ویژگی های سیستم های فرامتنی گذشته را ندارد، مانند Source Tracking، Fat Links و غیره. حتی برخی از ویژگی های فرامتنی که در ورژن های قبل تر HTML بودند تا همین اواخر توسط محبوب ترین مرورگرها نادیده گرفته می شدند، مانند عنصر link و ویرایش صفحه وب در مرورگر.
گاهی اوقات تولیدکننده های خدمات وب یا مرورگرها این نقص ها را برطرف می کنند. برای مثال، سایت های Wiki و سیستم های مدیریت محتوا به خوانندگان اجازه می دهند تا صفحات وبی که مشاهده می کنند را ویرایش کنند.
ویرایشگرهای WYSIWYG
برخی ویرایشگرهای WYSIWYG (What You See Is What You Get) وجود دارند که در آنها کاربر همه چیز را همان طوری که در سند HTML دیده می شود، با استفاده از یک رابط کاربری گرافیکی (GUI) می چیند که اغلب شبیه به پردازشگرهای متنی هستند. ویرایشگر به جای نشان دادن کد، متن را رندر می کند، بنابراین نویسندگان نیازی به داشتن دانش گسترده از HTML ندارند.
مدل ویرایش WYSIWYG عموما به خاطر کیفیت پایین کدهای تولید شده، مورد انتقاد قرار گرفته است. کسانی هستند که تغییر به مدل WYSIWYM (What You See Is What You Mean) را ترویج می کنند.
ویرایشگرهای WYSIWYG به خاطر نقص هایشان همواره یک موضوع بحث برانگیز خواهند بود، مانند:
– تکیه کردن بیشتر به چیدمان به جای معنا و استفاده اغلب از نشانه گذاری هایی که معنی مورد نظر را نمی رساند، بلکه فقط چیدمان را کپی می کند.
– اغلب کدهای طولانی و زائد تولید می کند که نمی توانند از قابلیت آبشاری HTML و CSS استفاده کنند.
– اغلب نشانه گذاری های غیرگرامری به نام Tag Soup یا نشانه گذاری های نادرست از نظر معنایی تولید می کند (مثلا <em> برای italics).
– به دلیل اینکه مقدار زیادی از اطلاعات در اسناد HTML در Layout قرار ندارد، این مدل به خاطر ماهیت “what you see is all you get” مورد انتقاد قرار گرفته است.
منابع: ویکی پدیا انگلیسی ، آریا گستر و …
توجه : مطالب و مقالات وبسایت آریاگستر تماما توسط تیم تالیف و ترجمه سایت و با زحمت فراوان فراهم شده است . لذا تنها با ذکر منبع آریا گستر و لینک به همین صفحه انتشار این مطالب بلامانع است !
دوره های آموزشی مرتبط


880,000 تومان

880,000 تومان

880,000 تومان
برچسبها:html, اچ تی ام ال
مطالب مرتبط










































































قوانین ارسال دیدگاه در سایت